Pricing Intelligence
This tweet has been making the rounds lately:
 Source: Twitter
Source: Twitter
Karpathy’s original post is this X thread. The claim is simple: if raw “intelligence” keeps getting more expensive to manufacture, the rich will be able to purchase meaningfully better minds than the rest of us.
This connects to broader questions about AI’s economic implications and how agentic systems might reshape value creation.
But is that inevitable? Smartphones, laptops, and even first‑class airline seats hint at subtler dynamics: the ultra‑premium tier rarely stays that far ahead of the median for long. So why should AI be any different — and if it is different, what breaks the historical pattern?
The Cost Structure of Intelligence
To understand where we’re headed, we need to first grasp why AI costs what it does today. The numbers are staggering.
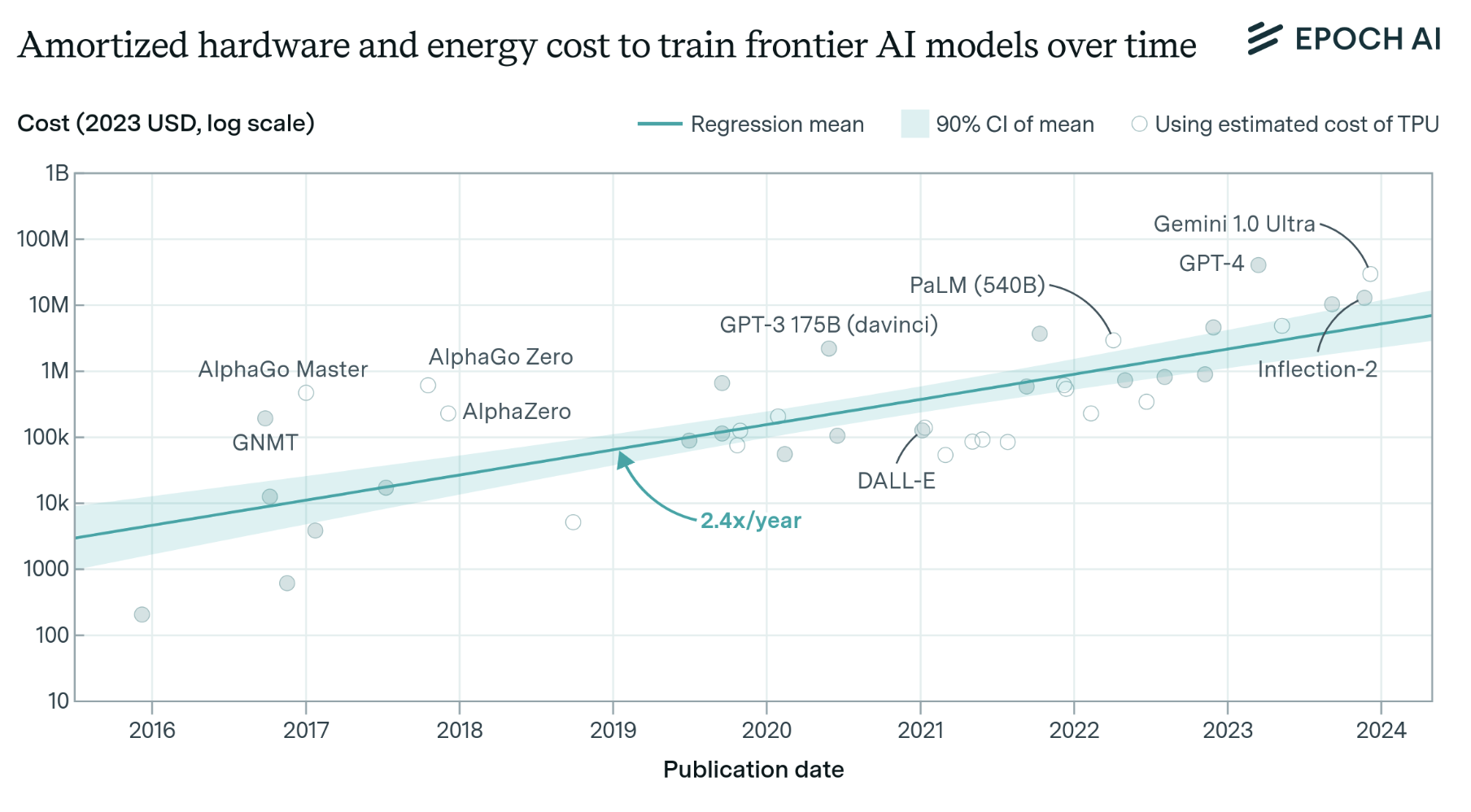 Source: Epoch AI
Source: Epoch AI
Epoch AI’s analysis shows that training costs for frontier models have been growing at 2.4x per year since 2016, with the latest models requiring hundreds of millions in compute alone. But what exactly drives these costs?
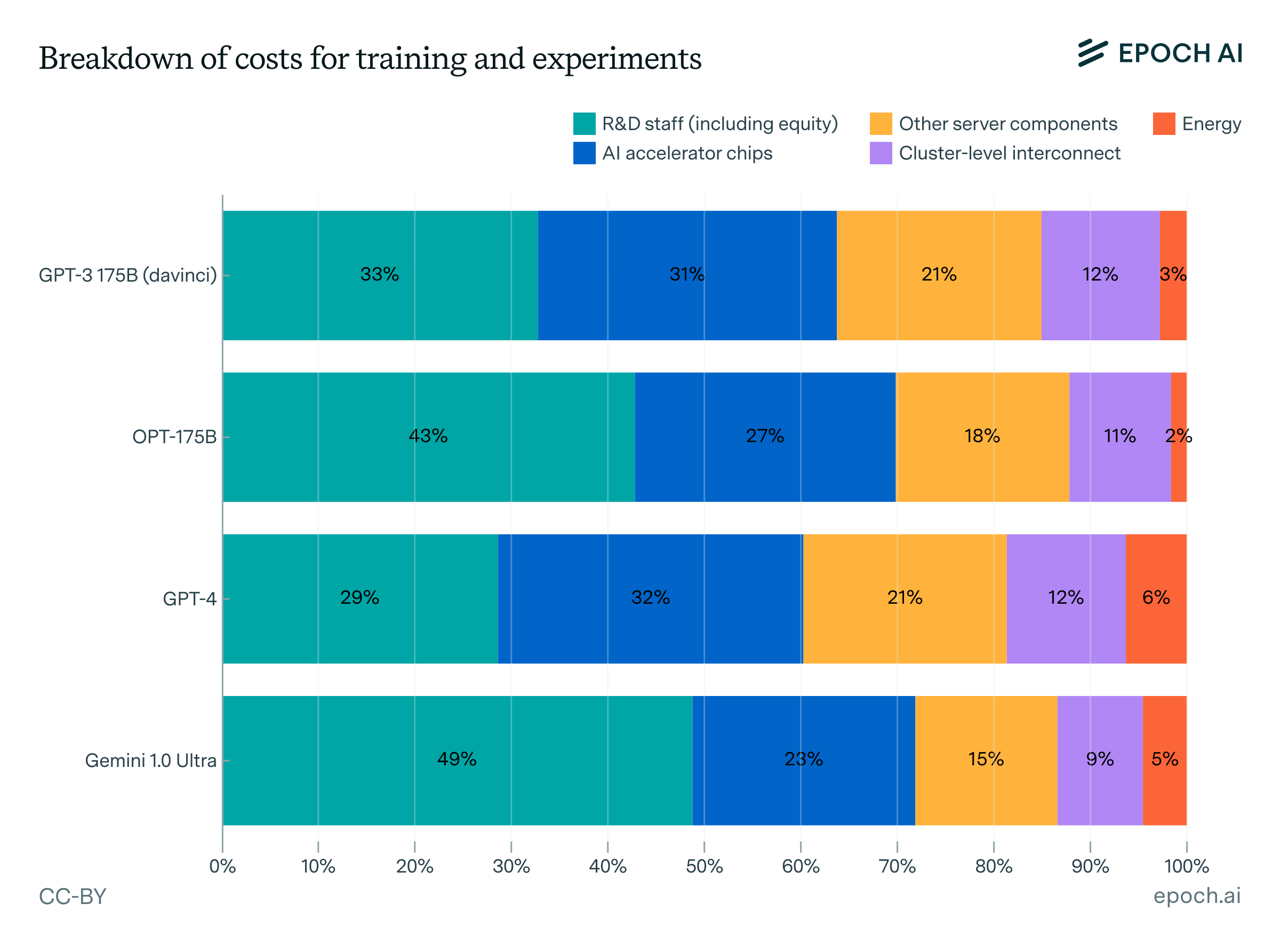 Source: Epoch AI
Source: Epoch AI
The breakdown reveals three major components:
- Hardware (47-67%): The GPUs and TPUs that power training runs
- Human capital (29-49%): The researchers and engineers, including their equity compensation
- Energy (2-6%): Surprisingly minimal compared to popular perception
This cost structure immediately suggests two key insights. First, the dominance of hardware costs means that improvements in chip efficiency directly translate to lower training costs. Second, the substantial human capital component creates a different kind of moat—one based on talent concentration rather than pure capital.
The Democratization Forces
While training costs grab headlines, they tell only half the story. Several powerful forces are working to democratize AI access:
Hardware Efficiency Gains
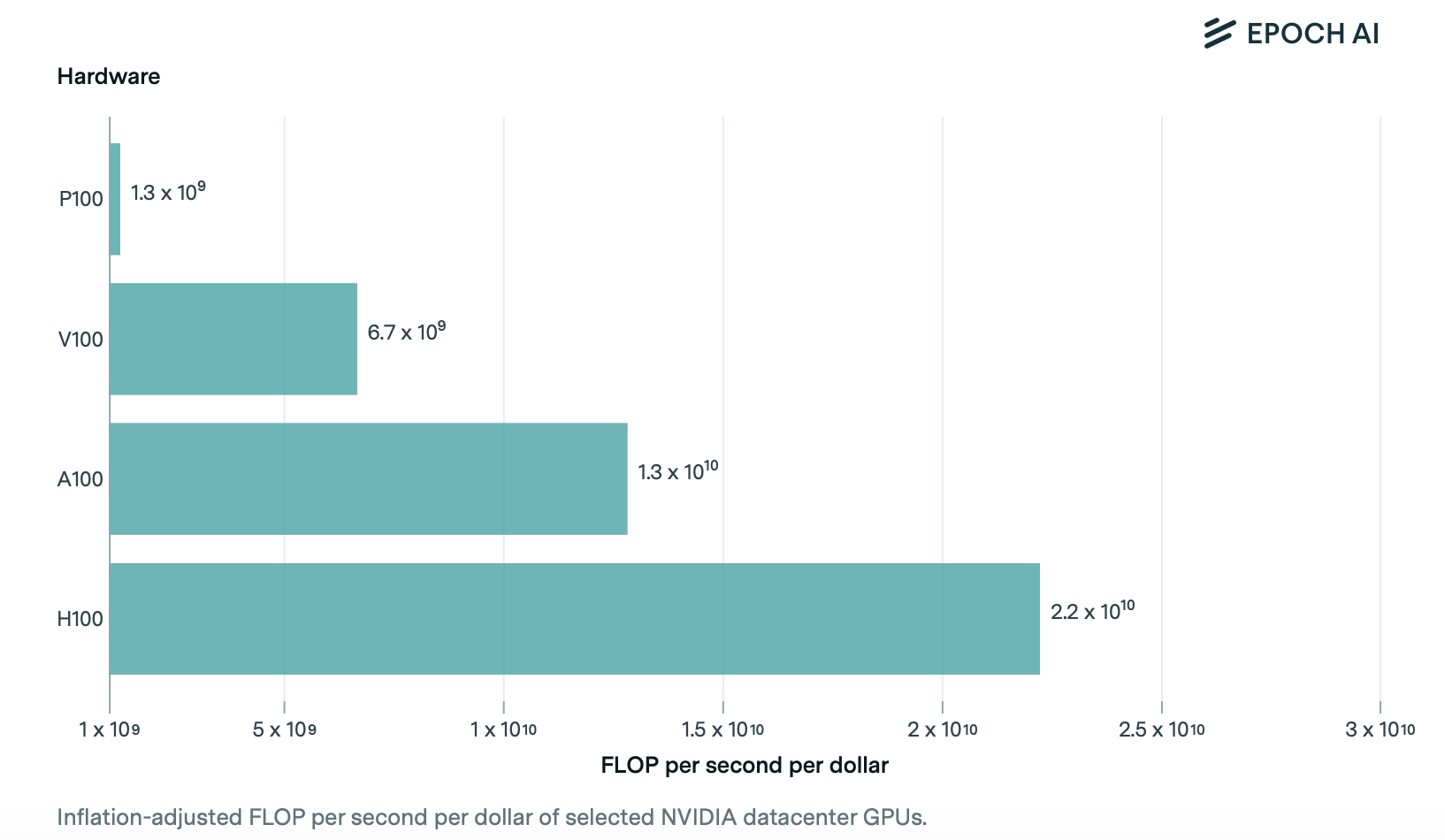 Source: Epoch AI
Source: Epoch AI
A quick back-of-the-envelope calculation, borrowing from Epoch’s insights: if frontier training compute demand shoots up ~2.6× a year, and hardware price/performance (FLOPs per dollar) improves by roughly 4.6x annually (a blend of new chip generations and architectural improvements), then effective compute-per-dollar for training swells by about 4.6x / 2.6x ≈ 1.8× annually.
Layer on algorithmic efficiencies, which Epoch AI estimates can deliver 3x effective capability improvements over time, and you’re suddenly squeezing ≈1.8x * 3x ≈ 5.4x more usable “intelligence” out of every dollar, every year, for a given level of capability. Money may chase bigger, more capable clusters, but each dollar is sprinting even faster down the cost-for-capability curve for yesterday’s SOTA.
Inference Cost Collapse
Training costs are one-time expenses, but inference—actually running the models—represents the ongoing operational cost. Here, the trends are even more dramatic.
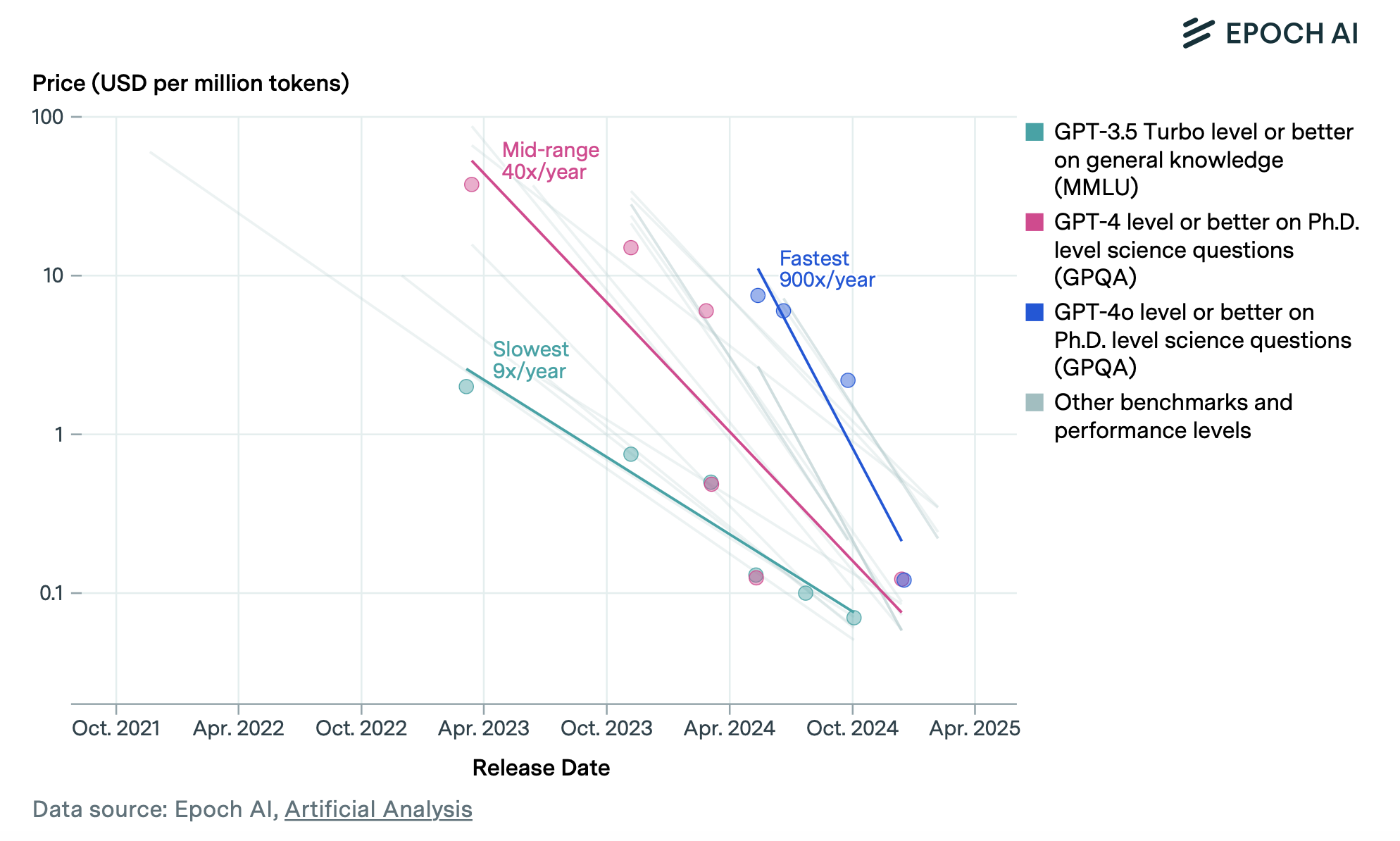 Source: Epoch AI
Source: Epoch AI
Inference costs have fallen by orders of magnitude, with some models now offering prices below $0.10 per million tokens. This collapse is driven by:
- Better hardware utilization through batching
- Quantization and model compression techniques
- Purpose-built inference chips
- Competition among providers
The Open Source Accelerant
Perhaps the most powerful democratization force is the rapid diffusion of knowledge through open source. Breakthrough architectures leak into the open within 6-12 months—fundamentally limits how long any company can maintain a capability moat.
The Aristocracy Forces
Despite these democratization pressures, several factors could sustain a “compute aristocracy”:
Scale Requirements Keep Growing
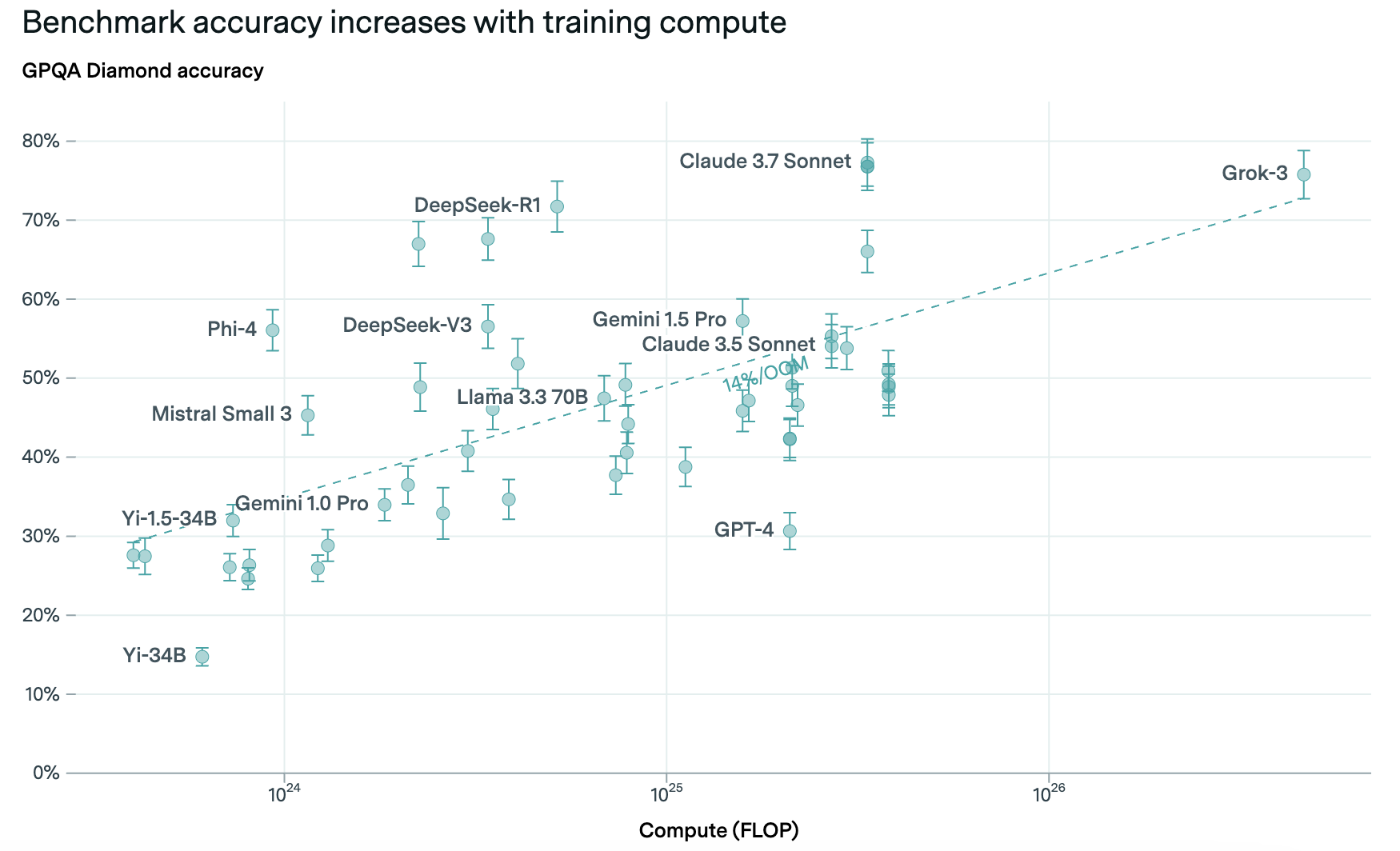 Source: Epoch AI
Source: Epoch AI
Performance continues to scale with compute, and the frontier keeps moving. As Dario Amodei noted, we’re nowhere near the limits of scaling laws. This creates a perpetual arms race where maintaining SOTA requires ever-larger investments.
Data as the New Moat
While compute is becoming commoditized, high-quality training data is becoming scarcer. The easy wins from scraping the internet are largely exhausted. Future gains may come from:
- Proprietary datasets (financial data, medical records, industrial telemetry)
- Synthetic data generation requiring massive compute
- Human feedback data that’s expensive to collect
 Source: Epoch AI
Source: Epoch AI
Companies with unique data access could maintain persistent advantages even as compute costs fall.
Regulatory Capture
Export controls on advanced chips, safety regulations on model sizes, and potential AI licensing requirements could artificially maintain scarcity. The recent US restrictions on chip exports to China demonstrate how regulation can create artificial scarcity in AI capabilities.
Integration and Deployment Costs
The gap between raw model capability and deployed product is substantial. Building the infrastructure to serve models at scale, ensure reliability, and integrate with existing systems requires expertise and capital beyond just training costs. This creates a different kind of moat—one based on operational excellence rather than raw capability.
Three Scenarios for AI Pricing
Based on these competing forces, I see three plausible scenarios:
Scenario A: Persistent Aristocracy (Unlikely)
In this world, the gap between frontier models and publicly available alternatives remains substantial:
- Export controls and data moats prevent capability diffusion
- Frontier models stay 2-3 years ahead of open alternatives
- Elite institutions pay millions for exclusive model access
- Cognitive inequality becomes a major political issue
If true, we’d see growing performance gaps between commercial and open models, successful regulatory capture by incumbents, and emergence of “AI inequality” as a political issue.
Scenario B: Rapid Democratization (Likely)
The historical pattern holds, and AI follows the path of previous technologies:
- Open source models lag by only 6-12 months
- Inference costs collapse to near-zero for most use cases
- Premium tiers exist but offer marginal improvements
We would see continued open source progress, sub-$0.001 per million token pricing, widespread deployment in education and small business.
Scenario C: Regulatory Freeze (Very Unlikely)
Safety concerns lead to aggressive regulation that freezes capability development:
- Model sizes capped at current levels pending safety frameworks
- Innovation shifts from capability to efficiency and application
- Everyone stuck at GPT-4 level for extended period
- Competition moves to integration and user experience
We come across a major AI safety incident, international coordination on model size limits, shift in research focus from scaling to efficiency.
The Historical Rhyme
The fear of a permanent “compute aristocracy” is understandable but likely overblown. Every transformative technology—from electricity to automobiles to computers—has followed a similar pattern: initial scarcity and exclusivity followed by rapid democratization. The forces pushing toward democratization in AI are, if anything, stronger than in previous technological waves.
What’s different this time isn’t the technology’s trajectory but its pace. The compression from “luxury” to “commodity” that took decades for automobiles or computers is happening in years for AI. This speed creates genuine challenges, but they’re challenges of adaptation, not access.